
1. 기존 벤치마크 데이터 셋의 한계
- 주로 짧은 응답을 요구하는 폐쇄형 질문에 모델을 평가하는 데 중점을 둡니다.
- 인간의 선호도가 배제되어 개방형 멀티턴으로 인간과 AI가 상호작용하는 대화를 평가하는데 적절하지 않습니다.
- 실제 서비스에서 많이 사용하게 될 챗봇모델보다 PLM모델이 득점을 많이 하게 됩니다.
- 사용자 선호도가 LLM 벤치마크 점수와 일치하는 것은 아닙니다.
- 특히 MMLU, HELM는 인간 선호도가 높은 모델을 효과적으로 구분을 할 수 없습니다.
- 출력과 참조 답변 간의 유사성을 기반으로 하는 기존 평가 지표(예: ROUGE, BLEU)는 개방형 질의문을 평가하는데 적합하지 않습니다.
1.1. 기존의 벤치마크는 주로 다음 세 가지 범주로 나뉨
Core-knowledge benchmarks(MMLU, HellaSwag, ARC, WinoGrande, HumanEval, GSM-8K, AGIEval) : zero/few shot 벤치마크 셋을 사용하여 사전 학습된 LLM의 핵심 능력을 평가하며, 일반적으로 LLM이 자동으로 검증할 수 있는 짧고 구체적인 답변을 생성하도록 요구합니다.
Instruction-following benchmarks(Flan, Self-instruct, NaturalInstructions, Super-NaturalInstructions) : 개방형 질문과 다양한 작업으로 확장되어 지시 미세 조정 후 LLM을 평가하는 데 사용됩니다.
Conversational benchmarks(CoQA, MMDialog, OpenAssistant) : MT-Bench 사용 사례에 가장 가깝다고 합니다. 그러나 이들의 질문의 다양성과 복잡성은 최신 챗봇의 능력을 평가하기에는 부족한 경우가 많습니다.
2. 새로운 벤치마크 데이터 셋의 필요성
2.1. 인간 피드백 기반 강화학습(RLHF; Reinforcement Learning with human feedback)
LLM-as-a-judge를 이해하기 위해서는 RLHF에 대한 개념이 잡혀 있어야 합니다. 간단한 학습 과정만 짚고 넘어가겠습니다.
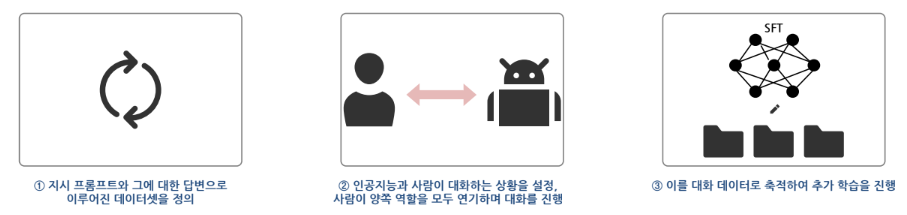
1단계 : 사람의 피드백을 기반으로 인공지능 모델을 학습
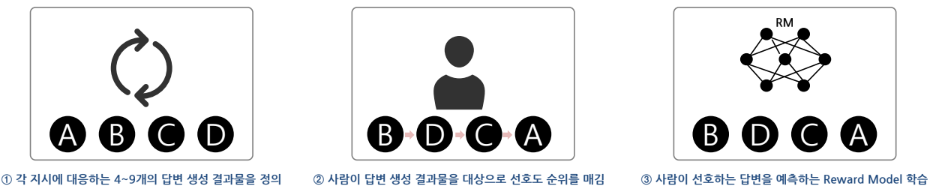
2단계 : 인간의 선호도를 반영한 Comparison 데이터 구축 및 Reward Model 학습
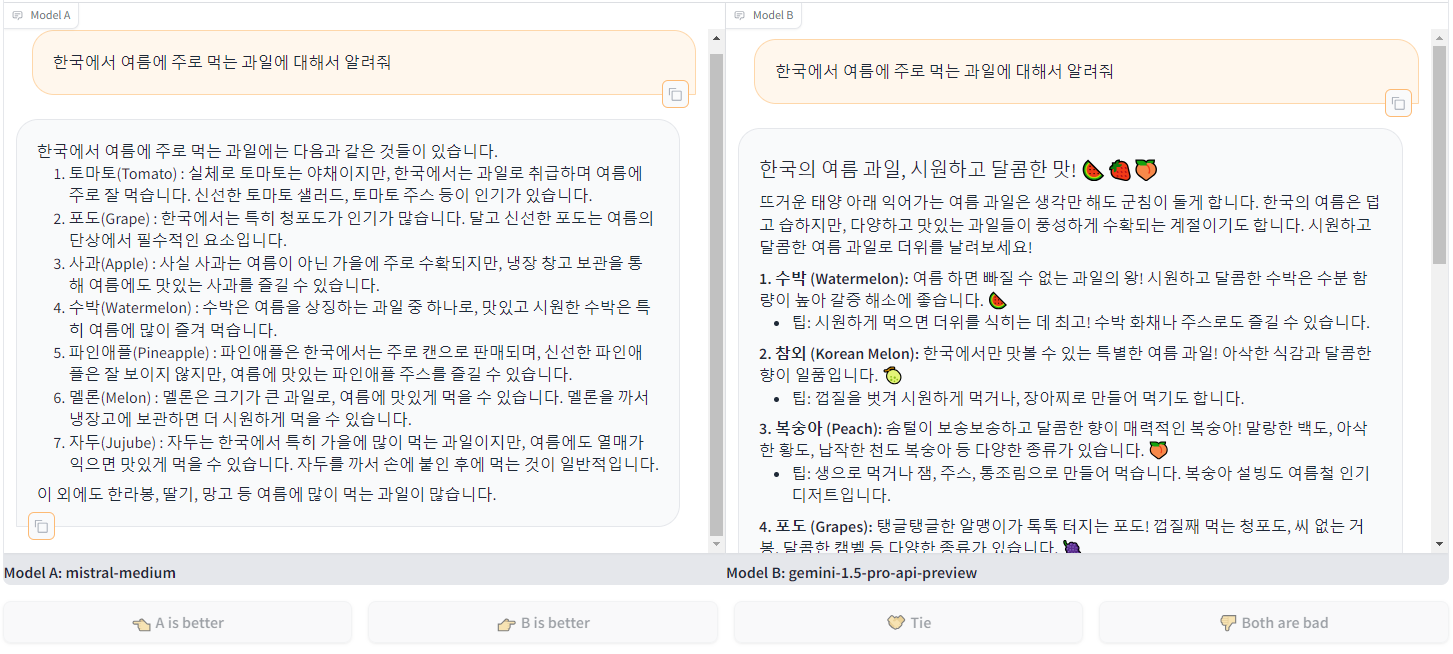
3단계 : Reward Model을 활용하여 강화학습 수행
1단계에서 학습한 대화형 인공지능과 2단계에서 학습한 Reward Model을 활용하여 챗봇의 성능을 향상시키는 과정입니다. 강화학습이란 agent가 특정 환경과 상호작용하여 주어진 상태에서 누적 보상 합을 최대로 하는 행동을 선택하는 최적의 정책을 스스로 찾아가는 학습 방법으로 agent는 보상을 최대화 하는 방향으로 정책을 지속적으로 업데이트하며, 환경은 계속해서 agent에게 보상을 주고 전이 확률에 따른 next state를 알려주어 이 과정을 여러 번 반복하여 답변의 품질을 향상 시킵니다.
2.2. MT-bench
인간 선호도의 두 가지 중요한 요소인 챗봇의 멀티턴 대화 및 지시 따르기 능력을 평가하는 일련의 개방형 질문 데이터 셋입니다. 일반적인 사용 사례를 포괄하고 모델을 차별화하기 위해 까다로운 질문에 초점을 맞춰 멀티턴 대화 및 지시 따르기 능력을 테스트하도록 설계되어 있습니다. 8가지 일반적인 사용자 프롬프트 범주로 구성됩니다(작문, 롤플레이, 추출, 추론, 수학, 코딩, 지식 I(STEM) 및 지식 II(인문/사회 과학)) 다음은 멀티턴 질문의 예시입니다.

2.3. Chatbot Arena
실제 시나리오에서 익명의 챗봇 간 좋은 답변을 선택하는 크라우드소싱 플랫폼으로 사용자는 두 챗봇과 동시에 대화에 참여하고 개인 취향에 따라 답변을 평가합니다. 이 플랫폼은 미리 정의된 질문을 사용하지 않으므로 사용자의 다양한 관심사에 따라 제한되지 않은 광범위한 사용 사례와 실제 투표를 수집할 수 있습니다. Chatbot Arena(https://chat.lmsys.org/)
3. LLM-as-a-judge
인간 평가는 인간 선호도를 평가하는 gold standard이지만 매우 느리고 비용이 많이 필요합니다. 따라서 GPT-4와 같은 LLM을 심사위원으로 활용해서 인간 평가의 gold standard와 비교하여 모델을 평가하는데 이러한 모델은 종종 RLHF로 훈련되기 때문에 이미 인간 선호도를 강하게 반영하고 있습니다. 장점으로는 1) 인간의 개입 필요성을 줄여 확장 가능한 벤치마크와 빠른 반복이 가능하다는 것과 2) LLM 심사위원이 점수뿐만 아니라 설명도 제공할 수 있다는 점을 들 수 있습니다.
3.1. LLM-as-a-judge의 유형
* Pairwise comparison
LLM 심사위원에게 질문과 두 가지 답변이 제시되고 어느 것이 더 나은지 또는 동점인지 결정하는 방식입니다.
* Single answer grading
LLM 심사위원에게 단일 답변에 직접 점수를 할당하도록 요청하는 방식입니다.

* Reference-guided grading
경우에 따라 해당되는 경우 참조 솔루션을 제공하여 평가를 요청하는 방식입니다.
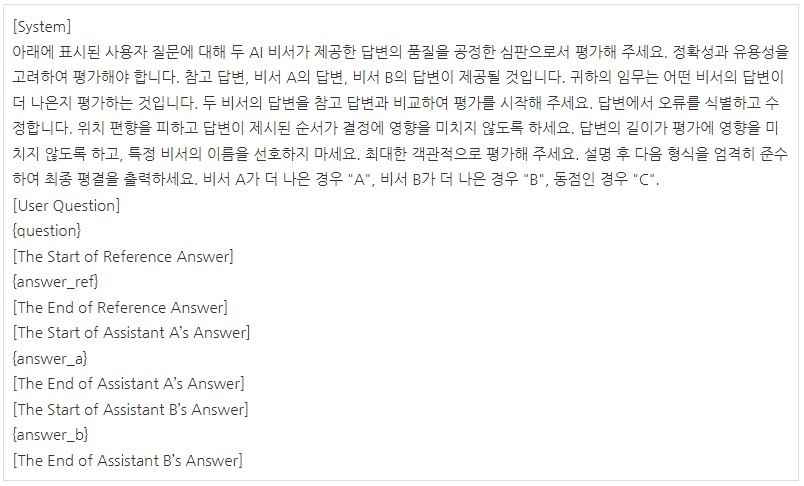
3.2. LLM-as-a-judge의 한계
* Position bias(위치 편향)
LLM이 특정 위치의 답변을 선호하는 경향성을 나타낼 때 발생합니다.
* Verbosity bias(장황함 편향)
LLM 심사위원이 더 짧고 명확하며 고품질이거나 정확한 답변보다 더 길고 장황한 답변을 선호하는 경향이 있습니다.
* Self-enhancement bias(자기 강화 편향)
일부 LLM 심사위원이 특정 모델을 선호하는 것을 관찰할 수 있었으나 데이터가 제한적이고 차이가 작기 때문에 이 연구에서는 모델이 자기 강화 편향을 나타내는지 여부를 결정할 수 없었습니다.
* Limited capability in grading math and reasoning questions(수학 및 추론 문제 채점 능력 제한)
GPT-4는 (별도로 질문할 경우) 문제를 풀 수 있음에도 불구하고 제공된 답변에 의해 잘못된 판단을 내렸습니다.

3.3 한계 해결 제시
* Swapping positions
두 답변의 순서를 바꿔 LLM 심사위원을 두 번 호출하고 두 순서 모두에서 답변이 선호되는 경우에만 승리를 선언하는 것으로 교체 후 결과가 일치하지 않으면 동점이라고 판단합니다. 또는 위치를 무작위로 할당합니다.
* Few-shot judge
퓨샷 예시가 위치 편향 벤치마크의 일관성을 향상시킬 수 있는지 평가합니다.
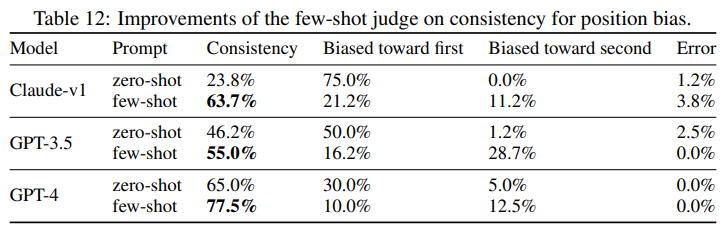
* Chain-of-thought and refrence-guided judge

CoT 프롬프트를 사용하더라도 많은 경우 LLM이 문제 해결 과정에서 실수를 범하는 것으로 나타났습니다. 따라서 먼저 LLM 심사위원의 답변을 독립적으로 생성한 다음 심사위원 프롬프트에 참조 답변으로 표시하는 참조 기반 방법으로 평가했습니다. 아래 표에서 기본 프롬프트에 비해 실패율이 크게 개선된 것을 볼 수 있음(70%에서 15%)

* 심사위원 모델 fine tuning
3.4. Multi-turn Judge
MT-Bench의 모든 질문은 대화 능력 평가를 위해 두 턴으로 구성되어 있음. 평가 디자인 후보는 다음 2개였습니다. (1) 두 턴을 두 개의 프롬프트로 나누는 방식 (2) 전체 대화를 단일 프롬프트에 표시하는 방식. 연구 결과, 전자의 경우 LLM 심사위원이 비서의 이전 답변을 정확하게 찾는 데 어려움을 겪을 수 있다는 것을 발견하면서 LLM 심사위원이 맥락을 더 잘 파악할 수 있도록 전체 대화를 단일 프롬프트에 표시하고 LLM 심사위원에게 두 번째 질문에 집중하도록 요청하는 2번을 채택하게 되었습니다.
4. 결론
- MT-Bench : 통제된 인간 평가를 통한 소규모 연구
- Chatbot Arena : 실제 환경에서 크라우드 소싱된 인간 평가를 통한 대규모 연구
- GPT-4 심사위원의 평가가 인간 평가와 높은 합의점을 도출함
- G4-Pair 및 G4-Single은 각각 쌍별 비교 및 단일 답변 채점 방식을 사용하는 GPT-4를 나타냄
- S1 : 비동점, 동점 및 불일치(위치 편향으로 인한) 투표를 포함하고 불일치를 동점으로 간주함
- S2 : 비동점 투표만 포함
- 각 설정에서 두 명의 무작위 심사위원 간의 합의는 "R="로 표시됨 각 셀의 맨 위 값은 합의도이며 아래 회색 값은 투표 수(#votes)
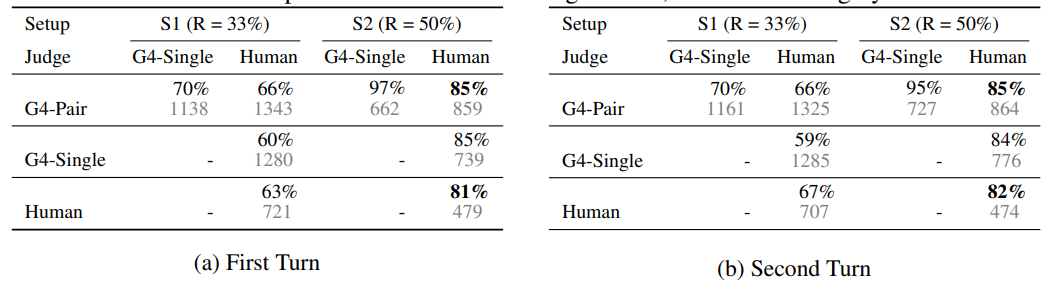
따라서 단일 벤치마크만으로는 모델 품질을 결정할 수 없으므로 종합적인 평가가 필요하며, 인간의 선호도를 근사화하기 위해 LLM-as-a-judge를 사용하는 것은 효과적인 LLM 평가방법이 될 수 있습니다.
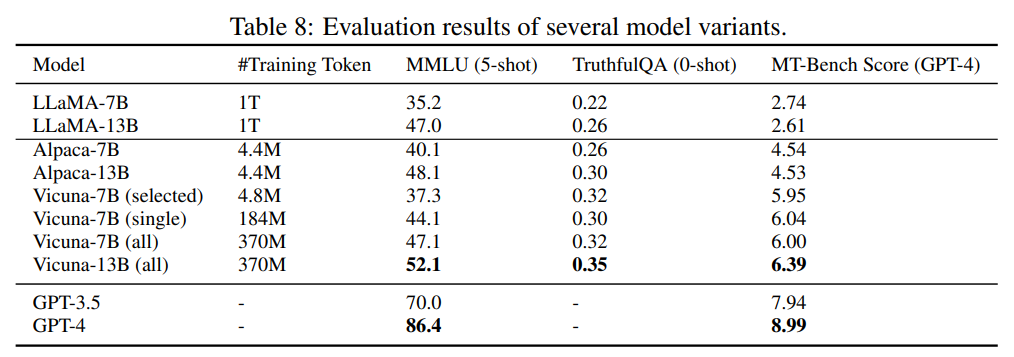
1. 기존 벤치마크 데이터 셋의 한계
- 주로 짧은 응답을 요구하는 폐쇄형 질문에 모델을 평가하는 데 중점을 둡니다.
- 인간의 선호도가 배제되어 개방형 멀티턴으로 인간과 AI가 상호작용하는 대화를 평가하는데 적절하지 않습니다.
- 실제 서비스에서 많이 사용하게 될 챗봇모델보다 PLM모델이 득점을 많이 하게 됩니다.
- 사용자 선호도가 LLM 벤치마크 점수와 일치하는 것은 아닙니다.
- 특히 MMLU, HELM는 인간 선호도가 높은 모델을 효과적으로 구분을 할 수 없습니다.
- 출력과 참조 답변 간의 유사성을 기반으로 하는 기존 평가 지표(예: ROUGE, BLEU)는 개방형 질의문을 평가하는데 적합하지 않습니다.
1.1. 기존의 벤치마크는 주로 다음 세 가지 범주로 나뉨
Core-knowledge benchmarks(MMLU, HellaSwag, ARC, WinoGrande, HumanEval, GSM-8K, AGIEval) : zero/few shot 벤치마크 셋을 사용하여 사전 학습된 LLM의 핵심 능력을 평가하며, 일반적으로 LLM이 자동으로 검증할 수 있는 짧고 구체적인 답변을 생성하도록 요구합니다.
Instruction-following benchmarks(Flan, Self-instruct, NaturalInstructions, Super-NaturalInstructions) : 개방형 질문과 다양한 작업으로 확장되어 지시 미세 조정 후 LLM을 평가하는 데 사용됩니다.
Conversational benchmarks(CoQA, MMDialog, OpenAssistant) : MT-Bench 사용 사례에 가장 가깝다고 합니다. 그러나 이들의 질문의 다양성과 복잡성은 최신 챗봇의 능력을 평가하기에는 부족한 경우가 많습니다.
2. 새로운 벤치마크 데이터 셋의 필요성
2.1. 인간 피드백 기반 강화학습(RLHF; Reinforcement Learning with human feedback)
LLM-as-a-judge를 이해하기 위해서는 RLHF에 대한 개념이 잡혀 있어야 합니다. 간단한 학습 과정만 짚고 넘어가겠습니다.
1단계 : 사람의 피드백을 기반으로 인공지능 모델을 학습
2단계 : 인간의 선호도를 반영한 Comparison 데이터 구축 및 Reward Model 학습
3단계 : Reward Model을 활용하여 강화학습 수행
1단계에서 학습한 대화형 인공지능과 2단계에서 학습한 Reward Model을 활용하여 챗봇의 성능을 향상시키는 과정입니다. 강화학습이란 agent가 특정 환경과 상호작용하여 주어진 상태에서 누적 보상 합을 최대로 하는 행동을 선택하는 최적의 정책을 스스로 찾아가는 학습 방법으로 agent는 보상을 최대화 하는 방향으로 정책을 지속적으로 업데이트하며, 환경은 계속해서 agent에게 보상을 주고 전이 확률에 따른 next state를 알려주어 이 과정을 여러 번 반복하여 답변의 품질을 향상 시킵니다.
2.2. MT-bench
인간 선호도의 두 가지 중요한 요소인 챗봇의 멀티턴 대화 및 지시 따르기 능력을 평가하는 일련의 개방형 질문 데이터 셋입니다. 일반적인 사용 사례를 포괄하고 모델을 차별화하기 위해 까다로운 질문에 초점을 맞춰 멀티턴 대화 및 지시 따르기 능력을 테스트하도록 설계되어 있습니다. 8가지 일반적인 사용자 프롬프트 범주로 구성됩니다(작문, 롤플레이, 추출, 추론, 수학, 코딩, 지식 I(STEM) 및 지식 II(인문/사회 과학)) 다음은 멀티턴 질문의 예시입니다.
2.3. Chatbot Arena
실제 시나리오에서 익명의 챗봇 간 좋은 답변을 선택하는 크라우드소싱 플랫폼으로 사용자는 두 챗봇과 동시에 대화에 참여하고 개인 취향에 따라 답변을 평가합니다. 이 플랫폼은 미리 정의된 질문을 사용하지 않으므로 사용자의 다양한 관심사에 따라 제한되지 않은 광범위한 사용 사례와 실제 투표를 수집할 수 있습니다. Chatbot Arena(https://chat.lmsys.org/)
3. LLM-as-a-judge
인간 평가는 인간 선호도를 평가하는 gold standard이지만 매우 느리고 비용이 많이 필요합니다. 따라서 GPT-4와 같은 LLM을 심사위원으로 활용해서 인간 평가의 gold standard와 비교하여 모델을 평가하는데 이러한 모델은 종종 RLHF로 훈련되기 때문에 이미 인간 선호도를 강하게 반영하고 있습니다. 장점으로는 1) 인간의 개입 필요성을 줄여 확장 가능한 벤치마크와 빠른 반복이 가능하다는 것과 2) LLM 심사위원이 점수뿐만 아니라 설명도 제공할 수 있다는 점을 들 수 있습니다.
3.1. LLM-as-a-judge의 유형
* Pairwise comparison
LLM 심사위원에게 질문과 두 가지 답변이 제시되고 어느 것이 더 나은지 또는 동점인지 결정하는 방식입니다.
* Single answer grading
LLM 심사위원에게 단일 답변에 직접 점수를 할당하도록 요청하는 방식입니다.
* Reference-guided grading
경우에 따라 해당되는 경우 참조 솔루션을 제공하여 평가를 요청하는 방식입니다.
3.2. LLM-as-a-judge의 한계
* Position bias(위치 편향)
LLM이 특정 위치의 답변을 선호하는 경향성을 나타낼 때 발생합니다.
* Verbosity bias(장황함 편향)
LLM 심사위원이 더 짧고 명확하며 고품질이거나 정확한 답변보다 더 길고 장황한 답변을 선호하는 경향이 있습니다.
* Self-enhancement bias(자기 강화 편향)
일부 LLM 심사위원이 특정 모델을 선호하는 것을 관찰할 수 있었으나 데이터가 제한적이고 차이가 작기 때문에 이 연구에서는 모델이 자기 강화 편향을 나타내는지 여부를 결정할 수 없었습니다.
* Limited capability in grading math and reasoning questions(수학 및 추론 문제 채점 능력 제한)
GPT-4는 (별도로 질문할 경우) 문제를 풀 수 있음에도 불구하고 제공된 답변에 의해 잘못된 판단을 내렸습니다.
3.3 한계 해결 제시
* Swapping positions
두 답변의 순서를 바꿔 LLM 심사위원을 두 번 호출하고 두 순서 모두에서 답변이 선호되는 경우에만 승리를 선언하는 것으로 교체 후 결과가 일치하지 않으면 동점이라고 판단합니다. 또는 위치를 무작위로 할당합니다.
* Few-shot judge
퓨샷 예시가 위치 편향 벤치마크의 일관성을 향상시킬 수 있는지 평가합니다.
* Chain-of-thought and refrence-guided judge
CoT 프롬프트를 사용하더라도 많은 경우 LLM이 문제 해결 과정에서 실수를 범하는 것으로 나타났습니다. 따라서 먼저 LLM 심사위원의 답변을 독립적으로 생성한 다음 심사위원 프롬프트에 참조 답변으로 표시하는 참조 기반 방법으로 평가했습니다. 아래 표에서 기본 프롬프트에 비해 실패율이 크게 개선된 것을 볼 수 있음(70%에서 15%)
* 심사위원 모델 fine tuning
3.4. Multi-turn Judge
MT-Bench의 모든 질문은 대화 능력 평가를 위해 두 턴으로 구성되어 있음. 평가 디자인 후보는 다음 2개였습니다. (1) 두 턴을 두 개의 프롬프트로 나누는 방식 (2) 전체 대화를 단일 프롬프트에 표시하는 방식. 연구 결과, 전자의 경우 LLM 심사위원이 비서의 이전 답변을 정확하게 찾는 데 어려움을 겪을 수 있다는 것을 발견하면서 LLM 심사위원이 맥락을 더 잘 파악할 수 있도록 전체 대화를 단일 프롬프트에 표시하고 LLM 심사위원에게 두 번째 질문에 집중하도록 요청하는 2번을 채택하게 되었습니다.
4. 결론
- MT-Bench : 통제된 인간 평가를 통한 소규모 연구
- Chatbot Arena : 실제 환경에서 크라우드 소싱된 인간 평가를 통한 대규모 연구
- GPT-4 심사위원의 평가가 인간 평가와 높은 합의점을 도출함
- G4-Pair 및 G4-Single은 각각 쌍별 비교 및 단일 답변 채점 방식을 사용하는 GPT-4를 나타냄
- S1 : 비동점, 동점 및 불일치(위치 편향으로 인한) 투표를 포함하고 불일치를 동점으로 간주함
- S2 : 비동점 투표만 포함
- 각 설정에서 두 명의 무작위 심사위원 간의 합의는 "R="로 표시됨 각 셀의 맨 위 값은 합의도이며 아래 회색 값은 투표 수(#votes)
따라서 단일 벤치마크만으로는 모델 품질을 결정할 수 없으므로 종합적인 평가가 필요하며, 인간의 선호도를 근사화하기 위해 LLM-as-a-judge를 사용하는 것은 효과적인 LLM 평가방법이 될 수 있습니다.